

Series: Rethinking
“The single biggest problem in communication is the illusion that it has taken place.” — George Bernard Shaw
Every enterprise transaction carries this illusion: the false belief that a message was understood simply because it was spoken or sent. Data leaves one system, travels through PDFs, emails, and manual re-entry, and arrives in another system — and everyone involved believes the two systems have communicated. They have not. What actually happened was a relay race, with humans and bots carrying the baton between applications that cannot hear each other. The data moved but the meaning did not.
In brief: The B2B transaction problem is not a people problem or a technology problem. It is a network problem — and it needs a network solution. When you build an Intelligent Transaction Network between systems and let AI operate inside it, systems that currently exchange data through documents and re-entry begin to understand each other. The transaction becomes intelligent, and the professional who governs it does more valuable work.
The Transaction Today
A container of automotive parts ships from Pune to Stuttgart. The Indian manufacturer’s ERP has all the data — commercial invoice, packing list, cargo specifications, and HS commodity codes — structured and clean, sitting in a database. The freight forwarder in Mumbai receives the shipment documents as PDF email attachments. Their operations team reads them, enters the cargo details into the forwarder’s transport management system, generates the bill of lading, files an export declaration with Indian customs through a separate government portal, books an ocean carrier slot through yet another system, and sends an advance shipping notice to the German logistics provider at the other end.
At every handoff, someone is reading a document that was generated from one system and typing its contents into another. The export declaration alone pulls data from three places — the manufacturer’s invoice, the forwarder’s booking confirmation, and the carrier’s vessel schedule — and none of those systems have ever exchanged a byte directly. A person assembles the declaration by opening three screens and copying between them.
By the time the container reaches Hamburg, it will have passed through at least nine separate systems spanning six organisations: customs on both ends, the shipping line’s operations platform, the port terminal systems, the destination logistics provider, and the consignee’s ERP. At every organisational boundary, the same thing happens — structured data gets wrapped in a document, emailed across, and re-entered by hand into the next system in the chain.

I have called this pattern software-driven labour in earlier articles — the manual operation of software interfaces to bridge integration gaps between core systems. The people doing this work are the workaround layer (Box B) that exists because the applications themselves (Box A) cannot interoperate. They are human middleware, carrying data between screens that should be exchanging it directly. The cost runs above $400 billion a year globally, taking in BPO operations, back-office processing, shared services, and the growing army of bots and AI agents deployed to make this work faster rather than to make it unnecessary.
What Has Been Tried
The industry has taken three runs at this problem. None of them worked.
Canonicalisation — driving every participant onto a single data standard — is the oldest. The idea is sound: if everyone speaks the same language, translation becomes unnecessary. Lloyd’s tried it with Kinnect, a market-wide initiative that aimed to standardise how brokers, carriers, and managing agents exchanged placement data. Twenty-two of 213 managing agents got there. The logistics industry has its own version — decades of effort around EDI standards, which have landed in customs declarations and high-volume shipper-to-carrier corridors, but the typical freight forwarder still books a shipping line through a web portal and sends trade documentation by email. Healthcare has HL7. Banking has ISO 20022. Each has achieved real adoption in specific high-volume corridors, and each has left the long tail untouched. Canonicalisation fails at scale because it places the onus to comply on every participating system: each application must be modified, each organisation must adopt the standard, and each must maintain compliance as the standard evolves. The economics work for the ten biggest connections. They do not work for the ten thousand smaller ones (see Rethinking AI for Automation for how this onus-to-comply principle shapes the economics of the long tail).
Verticalised platforms are the second attempt — a single player builds the infrastructure and invites the industry onto it. Maersk and IBM tried this with TradeLens, a blockchain-based logistics platform launched in 2018. It attracted genuine early participation from ports, freight forwarders, and some carriers. It shut down in 2022. Maersk’s own announcement cited the need for “a fully neutral, industry-wide platform.” Competing shipping lines declined to operate on a competitor’s infrastructure. The insurance market has seen similar attempts — carrier-led portals that aim to become the industry standard but never extend beyond the sponsoring carrier’s existing book. The structural problem is always the same: the entities whose participation would create the network effects are the entities that will not join a platform owned by their competitor (see Rethinking the Data Moat for why player-led platforms fail structurally).
The self-service portal is the third — and the most common by far. A shipping line builds a booking portal and tells forwarders to use it. An insurance carrier builds a submission portal for brokers. A bank builds a trade finance application for corporate clients. Each provider presents this as “digital” or “B2B straight-through processing,” and in each case what actually happened is that the data entry work moved from one organisation to another. The forwarder’s operations team now log into the shipping line’s portal and manually key in data that already exists in their own TMS — and they repeat this for every carrier they work with. Twenty shipping lines means twenty portals. The data was digital before anyone started typing.
A large number of these portal victims — and that is the right word — end up deploying RPA bots to automate the form-filling. That is a point-to-point workaround layered on top of another point-to-point workaround. One automated leg does not make the chain automated. And then there is the power dynamic that I have watched play out in insurance, logistics, and trade finance alike: a larger counterparty, or a more transactionally valuable one, refuses to use the portal. They push back. “Here is our data as email attachments. Do the form-filling yourself.” A very large number of self-service portal providers are living with exactly this predicament right now, across domains and verticals, and most of them have no answer for it.
All three approaches solve one problem and create another. Canonicalisation solves translation but creates a compliance burden that the long tail cannot bear. Verticalised platforms solve connectivity for the sponsor’s existing clients but create a trust problem that blocks network-wide adoption. Self-service portals solve the provider’s data capture problem but push the cost of integration onto the counterparty — who absorbs it, automates around it with bots, or refuses it entirely. The fix has to solve all three without creating any of them.
The Fix
The fix is a specific kind of architecture, and the technology to build it already exists. Take the same AI that currently reads PDFs and runs agentic workflows in Box B — semantic understanding, contextual reasoning, adaptive learning — and move it into the space between systems. What you build is an Intelligent Transaction Network — an ITN: a network that sits between applications, understands what they mean, mediates between them semantically as transactions flow through, and gets smarter with every transaction it processes.


First: it understands meaning, not just structure. Traditional integration maps fields — “HS_code” in one system corresponds to “tariff_classification” in another. Someone built that mapping by hand, tested it, and maintains it. Multiply that work by every field in every transaction type in every counterparty relationship, and you have the long tail of integration: the vast number of small integration cases, each too expensive to automate individually but collectively enormous. That is why most of these connections never get built.
This network does something different. It grasps the data models of the systems it connects — what the fields mean in context, how they relate to each other, and what business rules they encode. When the manufacturer’s cargo description says “automotive brake assemblies, hydraulic, for passenger vehicles” and the customs portal needs an HS classification to six digits plus national subheading, the network does more than match text strings. It understands the commodity well enough to classify it correctly, and it flags the ambiguous cases — because in cross-border trade, a wrong HS code means a wrong duty rate, and a wrong duty rate means the shipment sits in a bonded warehouse while somebody sorts it out.
An experienced freight coordinator or customs broker does this work today. They understand what the data means, not what format it arrives in. Large language models can do the same — the same models currently aimed at reading PDFs and extracting text could be interpreting application data models and mediating between systems that were never designed to talk to each other. And layers of agentic AI sit beneath the semantic layer to handle the operational work — connecting to applications, monitoring data flows, managing exceptions, and adapting when something in the chain changes. The semantic layer understands meaning; the agentic layer acts on that understanding.

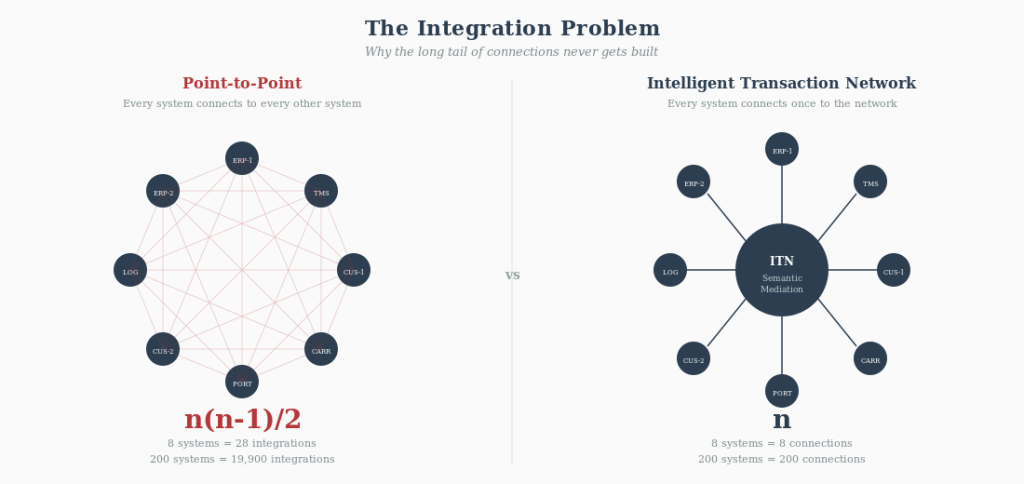
A critical structural point: each participant connects to the network once, in whatever data format they already use. The network handles the translation to every other participant. Two hundred counterparties means two hundred connections, not twenty thousand point-to-point integrations that each need to be built, tested, and maintained. That is the structural difference between an ITN and a conventional integration programme — and it is why the long tail becomes solvable. The combinatorial explosion that makes point-to-point integration impossible at scale simply does not apply when every participant connects to a common semantic layer that handles the mediation. Unlike canonicalisation, it does not ask anyone to change their systems. Unlike a verticalised platform, it is not owned by a competitor. And unlike a self-service portal, it does not push the work onto the counterparty — nobody logs into anyone else’s application to fill in a form. The data flows from system to system through the network, and the humans involved spend their time on judgment, not on data entry.
Second: it orchestrates transactions, not just data. The Pune-to-Stuttgart shipment touches nine systems in six organisations. Today, a freight coordinator walks the transaction through each step — booking the carrier, filing customs declarations, arranging marine cargo insurance, and notifying the consignee’s warehouse. She holds the thread. When something goes wrong — and in cross-border logistics, something always goes wrong, whether it is a vessel delay, a documentation discrepancy, or a regulatory hold — she diagnoses, adjusts, and re-routes.
The network can orchestrate in her place — not through rigid if-then rules that break the first time something unexpected happens, but by understanding what the transaction needs at each stage and adapting when conditions shift. A vessel delay triggers a rebooking assessment, a revised customs timeline, and an updated arrival notice to the destination warehouse, all because the network understands the dependencies between the steps well enough to respond on its own.
Third: it generates intelligence that no single participant can see. The network does not mediate one shipment and stop there. It processes transactions in volume — bookings, customs filings, bills of lading, carrier confirmations, and delivery receipts — from multiple shippers, forwarders, and carriers. Each transaction teaches the network something about how data moves in this market, where the friction concentrates, and which data representations cause problems at which boundaries.
That knowledge accumulates. In one deployment I was involved in — this one in the insurance market rather than logistics — the network identified a treaty clause that had been misinterpreted through an entire programme, because it had processed enough structurally similar transactions to recognise the pattern. The clause had been misapplied for two renewal cycles before anyone caught it. No individual participant had the visibility to spot the error, but the network did.
The same kind of pattern recognition works in every domain the network touches. Trade finance settlement anomalies, logistics routing bottlenecks, and insurance placement patterns all become visible when you see the full transaction chain — and none of it requires sharing proprietary data between participants. What accumulates is knowledge about how transactions flow and where they break, and that knowledge belongs to the network, not to any single participant.
Fourth: it adapts when systems change. Applications change. Vendors ship upgrades, regulators impose new data requirements, and counterparties update their formats. In the conventional integration world, every change triggers a maintenance cycle: regression testing, remapping, and reconfiguration. The network learns the semantics of each connected application, and when a vendor renames a set of fields or a customs authority changes its declaration format, the network recognises that the meaning has not changed even though the labels have, and adjusts on its own. The technology to do this is the same technology currently being aimed at reading PDFs, and the economics point in one direction only.
What the Professional Does
People talk about AI and professional roles in two ways — either everything gets replaced or nothing changes — and the real answer is more specific than either.
The freight coordinator managing the Pune-to-Stuttgart shipment currently spends most of her time on information transfer — reading documents, entering data into screens, and checking that what left one system arrived correctly in the next. Some of that work uses her expertise. Most of it just uses her eyes and her typing speed. The network handles the second category.
What she keeps is the work that actually draws on twenty years of cross-border trade experience — making the call when the HS classification is ambiguous, deciding whether a vessel delay warrants rerouting or just a revised schedule, and maintaining the carrier relationships that get her shipments priority handling when capacity is tight.
Her accountability does not change either. If the classification is wrong, the shipment is delayed and her client pays storage fees at the bonded warehouse. If the routing decision is bad, the cost lands on her desk. A system has terms of service; she has a client relationship and a professional reputation built one correct call at a time over twenty years. That accountability — professional and commercial, and in regulated industries legal — is the clearest justification for the margin, and no network touches it.
In one case I was directly involved in on the insurance side (because the pattern is identical in every domain), the AI flagged a risk profile for review. The underwriter overrode the flag — she had direct experience with that client and that risk class that gave her context the system could not access. She was right. That is what governance looks like in practice: the network presents structured analysis, and the professional decides. They work together because they are good at different things.
What the Network Requires
The network sits between organisations, mediating their transactions, which means every participant has to trust it. The TradeLens failure showed what happens when that trust is absent — and the verticalised platform section above explains why. The question is what governance model creates trust at scale.
The answer is SWIFT. Banks in 1973 faced the same structural problem: interbank messaging was fragmented, manual, and expensive, and no bank was willing to run its messages through a competitor’s system. So they built a cooperative — neutral governance, shared infrastructure, and no participant with a controlling interest. SWIFT now connects more than 11,000 institutions in over 200 countries. It works because the trust model is built into the architecture, not bolted on after the fact.
The ITN must be governed the same way. Data from each participant stays isolated — a forwarder’s routing strategy cannot be visible to a competing forwarder, and a carrier’s pricing signals cannot leak to the market. If the governance is wrong, adoption dies regardless of how good the technology is.
The network also has to work with the world as it is. Some counterparties will send PDFs for years. Some will send structured data. Some will send a combination that changes from month to month as they upgrade different parts of their stack at different speeds. Every previous approach to this problem — EDI, canonical formats, and industry data exchanges — demanded that the mess be cleaned up before the integration could work. The network works with the mess and cleans it up progressively. That is the architectural point.
The Same Shipment
The same container of automotive parts ships from Pune. The manufacturer’s ERP transmits structured shipment data — commercial invoice, packing list, and cargo specifications — to the network. The forwarder’s TMS sends its data in a different format. The customs portal on the Indian side still expects a specific XML schema. The German logistics provider sends a PDF confirmation because their system has not been upgraded in four years. The network takes all of it — structured data, legacy formats, and PDFs — and mediates between them. Where data models differ, the network translates. Where a document arrives instead of structured data, the network reads and interprets it the same way a person would, except faster and without re-keying. Where HS classifications are ambiguous, the network flags the problem before the shipment moves, with specific context about what is missing and what the options are.

The freight coordinator receives a structured decision package for the cases that need her judgment. The rest flows through without a person sitting between screens copying data from one to another. Nine systems, six organisations, and two customs jurisdictions — and the data moves from origin to destination whether it started as structured data or a PDF. The de-digitise-and-re-digitise cycle does not disappear overnight. It gets absorbed by the network, one connection at a time.
What took five days and eight people becomes same-day with one professional making the calls that need professional judgment. The bottleneck was never the people — it was the systems’ inability to understand each other, and the network removes that bottleneck.
For the diagnostic argument about why AI in the workaround layer deepens the problem it was meant to solve, see “Rethinking AI for Automation.” For why proprietary infrastructure fails as a moat and where the real competitive assets live, see “Rethinking the Data Moat.”
Madhav Sivadas is an enterprise software integration architect with nearly thirty years in process integration, UI automation, and enterprise workflow. He founded Inventys (acquired 2012), holds multiple US patents in software integration, and is the founder and CEO of Telligro, building AI-driven intelligent transaction networks for insurance, logistics, and financial intermediaries.