
Hyperautomation
Let there be no doubt that what is called hyperautomation is singularly and principally founded on RPA. If RPA had not become well known there would not have been any definition of hyperautomation.
Let us revisit Gartner’s definition of this term:
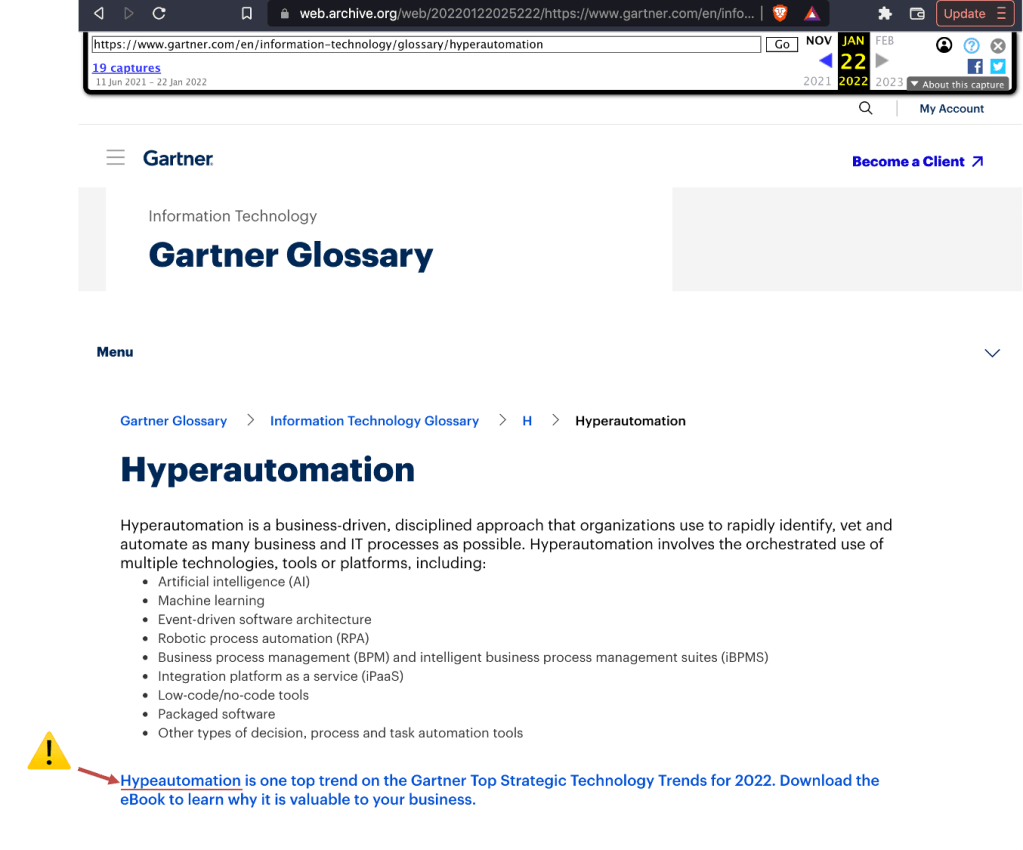
This image is a screenshot of an archive copy of their website taken by http://www.archive.org on 30 January 2022. I laughed to see the Freudian slip, a typo that would perhaps eventually get corrected, but nevertheless a fitting term that defines the state of this market.
The current players in this market segment are definitely peddling Hypeautomation!
Now, observe how the term is defined as an “approach” that can be used to “…automate as many business and IT processes as possible.”
Think! McFly! What do you mean “.. automate as many business and IT processes as possible”?
Would you buy a database if the vendor says that it will store as much data as possible, and for the rest you can use pen and paper?
The last bullet point in the definition of hyperautomation reveals the extent of their audacity at being considered by many as the custodian of technology definitions. According to their definition, hyperautomation involves the use of “other types of decision, process, and task automation tools”. That cannot be considered as leaving the door ajar. It is more like removing the door from the frame.
Our reason for creating this technology was to achieve application integration and portalisation. This is also reflected in the patent that we filed, which was subsequently granted. Our efforts to promote this technology in that category in APAC region was not well received by the IT departments of enterprises in the region. We knew that there is a definite need for this technology and therefore sought to promote it with the actual beneficiaries: the operations and business groups in various enterprises. Our success with this group lead us to potentially larger-scale opportunities that were found in contact-centers, back-offices, and BPOs. That is how this screen integration technology became a process automation technology.
My own “Mt Stupid” moment occurred a couple of years into the success that we found in BPOs — around 2013. I realised that the use of screen integration techniques through business-driven automation projects will never result in the elimination of software driven labour.
Call it by any name, and augment it with any ancillary technology, but RPA and hyperautomation in the hands of business operations teams will always remain a technology that promises to reduce the volume of human interventions; and it will never cause complete independence from software driven labour in enterprises.
The pointer to this fact is present in Gartner’s own definition of hyperautomation. Remember technology is only going to “.. automate as many business and IT processes as possible”.
Early investors like hypes, because it helps them inflate valuations and set the scene for liquidity events such as M&A and IPO. This, along with a rising sales momentum, forces many founders and promoters to keep climbing the hype curve.
This often results in the hyper-mess that the industry will find itself in after a few years of unsuccessful ventures.
The Problem
To understand the utter stupidity of the situation with hyperautomation, one needs to step back and view what really has happened.
The top block in the figure below depicts the Porter’s Value Chain model for a typical enterprise.
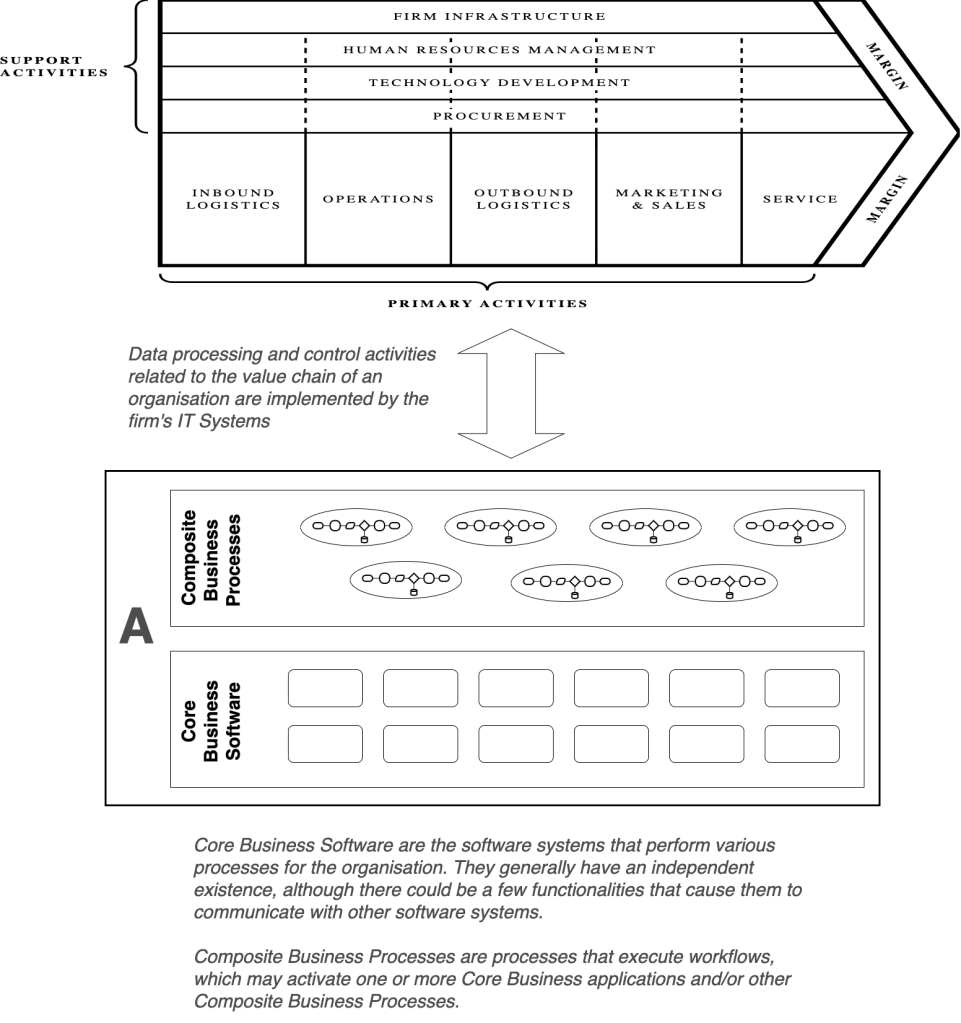
The Value Chain model organises a company into various blocks of activities. By definition, this model focuses on value-generating activities. It is recommended to be constructed and viewed at business unit level. But for this discussion, I am using the Value Chain model to represent the full set of activities that occur within an enterprise, regardless of whether those activities are explicitly generating “value”. The diagram is a good way of representing the broad categories of activities that enterprises have to perform.
Each of the blocks in the Value Chain model comprise of several business processes. These processes have corresponding mappings in the organisations’s IT systems. All facets of the business are managed through these data processing and control systems. As described in previous articles, almost everything that an organisation does is connected via some data processing component in the organisation’s IT systems.
An essential and fundamental objective of any organisation’s IT systems is to achieve straight through processing (STP) of all business activities that they participate in.
STP means that the processing steps that the IT systems perform should happen “straight through” and that there should be no technical hurdles preventing every subsequent step in the chain from getting performed.
STP does not mean that processes must complete in sub-second speed. There may be valid business requirements that require business processes to halt at certain points in their flow, and resume only when an appropriate business-specific trigger events occur.
However, it is incorrect to allow processes to halt due to:
- inability to interoperate between two or more software systems in order to keep the flow moving;
- waiting indefinitely for human input by allowing such actions to queue up and get processed by humans based on a “pull from queue” metaphor.
Background
In any enterprise, Box A represents those business processes and their corresponding software components that are performed automatically using data processing systems (IT systems).
We make the following assumptions here:
- All enterprises that we consider in this discussion perform 100% of their business data processing through software.
- There are no primary data destinations that are not electronic. Origins of data could be paper forms and non-digitised electronic media, and secondary data destinations could be paper ledgers and non-digitised electronic media; but primary destinations are all digitised into electronic media.
These assumptions are to ensure that we focus our discussion on organisations that are driven primarily via their IT systems – which they either own or rent.
Software systems and applications in Box A perform business use cases. These use cases are triggered by events, which could be based on a variety of conditions including time, arrival of other data, messages from other software systems, and human intervention.
Software applications may provide multiple interfaces to enable entities to communicate with them. A visual user interface (UI) enables humans to interact with the applications. The purpose of the visual user interface is:
- to perform processes that require data to be entered; and
- to retrieve and display data from the software system for a multitude of purpose including decision making, summarising, reporting, etc
Data entry using the visual UI of software applications enables software applications to exist independently. All the data that needs to be processed and stored by the system can be entered into the system via the user interface screens.
Complications
The various business processes in the value chain of an enterprise may involve activities performed on one isolated software component, or it may span across two or more software components.
In the diagram, Core Business Software layer represents the collection of systems and processes that can exist in more or less isolated from each other. These core systems may receive data via their respective UI or some other message channel.
Composite Business Processes layer represents the collection of systems and processes that essentially work by performing actions that span across two or more software systems. This type of orchestration of actions is achieved using various types of application integration technologies that help to transport data between applications and trigger the applications to perform some intended actions.
Complications in this world arise in two ways:
- The UI-driven data entry mechanism becomes too tedious to operate by humans as a result of:
- organic functionality enhancements: more screens and fields getting added in subsequent releases; and/or
- volume of inbound data increases beyond originally anticipated usage, thereby making it a formidable task to load incoming data via UI screens.
- It becomes technically infeasible to compose business process spanning certain systems because of integration and interoperation issues between the systems. These are hard technical limitations and incompatibilities.
In such scenarios, when software applications in the organisation are unable to form an “activity chain” of automatic processing, there is a breakage in straight through processing (STP). When this happens, the first resort is to get humans to use the visual UIs of the incompatible applications thus bridge the processing gap.
Large organisations that have many processes with broken STP resort to software driven labour deployed in shared services, back offices, and outsourced back offices.
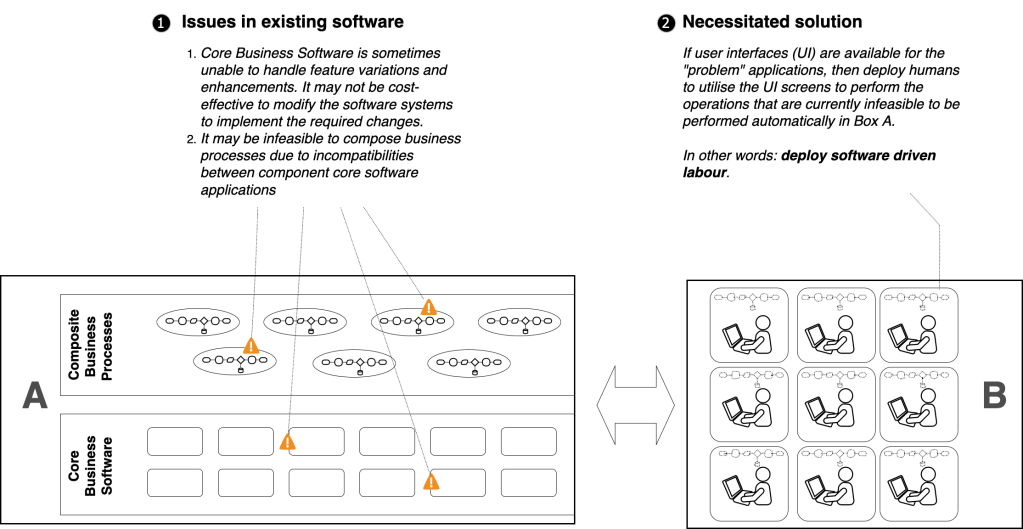
Box B represents the subset of business processes that are accomplished via software driven labour. There are two broad categories of use cases that involve software driven labour in business processes.
The first case is when data enters the organisation from an external source (outside the organisation). This could happen either via touch-points such as branches where, for example, customers walk-in and interact with staff or with a self-service software application in order to enter primary data. (define primary data: ) Another example of this category is when employees, customers, and partners make use of “self-service applications” that are provided by the recipient organisation to enter data via visual UI of these self-service applications.
The other scenario is when data enters an organisation from an external source via a rather unfortunate sequence of activities. In the source organisation, which also operates using software systems, digital data is “de-digitised” and converted into scanned document or de-formatted into PDFs and then sent over to the recipient organisation. It then enters the target organisation where a human re-digitises it. A third (hybrid) case could happen when a de-digitised document is uploaded to the receiver organisation via a self-service application provided by the receiver.
The second category of the use of software driven labour is when a business process in an organisation requires multiple software applications within the organisation to interoperate (that is, exchange data and control among each other), and if those software applications are not integrated to be able to send data and control messages between each other. In such situations, the user interfaces of the participating applications are used by humans to orchestrate the flow of data. For example, there could be a scenario where the ERP (enterprise resource planning) application does not automatically connect with a payment application, for the scenario of paying invoices. Therefore humans have to login to the ERP and retrieve the details of the invoice(s) to be paid and for each invoice they may have to open the payment application (banking application or SWIFT interface) and enter the payee details and amount from the invoice. This is a common and typical software driven labour scenario in many organisations.

By viewing the situation in this manner it is easy to understand the issue with prevailing process automation methods. The expected ideal mechanism is for the software systems to be integrated via traditional enterprise application integration technologies. If this is achieved, the necessary application-to-application interoperation will occur and business processes will execute without human intervention. When conventional integration does not work, there is a need to get humans to perform software-driven labour in order to bridge the automation “gaps”.
Our original intent when we created a UI Automation product was to to complement the traditional integration model with our then-disruptive mechanism to achieve application integration and portalisation. In order to sell the benefits of this technology, we presented it to business and operations groups in enterprises.
The mistake that occurred was that instead of treating this solution as an augmentation of enterprise application integration, the technology literally got hijacked by the business operations groups and deployed as an efficiency improving alternative to software driven labour by focusing purely on human actions automation. Why was that a mistake? Because the focus moved away from the enterprise software systems (box A). The actual data processing activity is, and has always been, at the core enterprise software applications level. Now, by focusing on human action automation we are creating new sets of problems and finding solutions to those problems.
For example, instead of devising mechanisms to automatically load pre-digitised data from invoices into the enterprise’s ERP, people are trying to use artificial intelligence, machine learning, deep learning, and all other fad-jargon-based technologies to try to visually interpret invoice documents. These incoming documents could be presented in the form of scanned images, PDF files, Excel spreadsheets etc. Machine learning based techniques are being deployed to locate and extract data fields from these documents!!
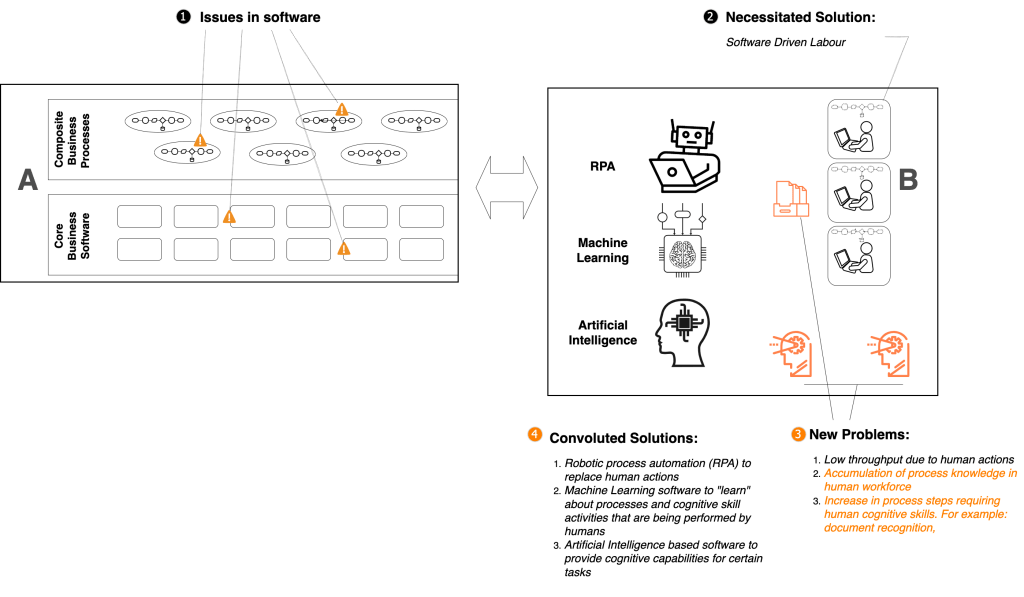
Hello? Hello? Anybody home? McFly?
The data in those scanned images and PDFs etc were once in digital form in other organisations’ data processing systems. Due to archaic practices, enterprises indulged in sending hard-copy artifacts to each other; and subsequently this was “upgraded” to sending the same documents as email attachments.
When viewed from a business operations automation perspective, it is possible that people only see the set of events occurring in Box B. From this perspective, the solution for automating heterogeneous inbound documents may seem to lie in crazy things like optical character recognition (OCR), computer vision (CV), deep learning convolutional neural networks, etc. These “solutions” are attempting to replace the way a human would glance at an invoice (for example) and quickly locate the various data fields that need to be extracted.
This line of thinking leads to various complexities. There is a misconception that “process knowledge” lies with the entities dominating Box B – the business operations and back-office staff. In an overwhelming majority of cases, these teams do not have accurate and updated process-flow definitions. There may exist persons who are designated “subject matter experts” (SMEs), who are supposed to know detailed use cases and sub-scenarios of certain business processes. However, in reality much of this knowledge could be out-dated. To discover these details accurately, another AI based tool is required that can record business users performing their routine software driven labour activities, and use the collected data to find common patterns of process flows. Once these flows are “discovered” or “mined”, they can be sent to an RPA tool for conversion into process automation definitions.
The real problem is in Box A, where the actual enterprise data processing systems are deployed; and solutions to the problem should focus on mending and enhancing the interoperation of software systems in their native environment.
Think! McFly!
The components in Box B were intended to enable humans to interface with components in Box A to overcome integration and interoperation issues in Box A. It was meant to be a temporary and stop-gap solution to be used until the systems in Box A are enhanced and made interoperable.

Here is the irony: in order to address issues in Box B, organisations have introduced all kinds of complex AI-based tools that attempt to think like humans to automate steps that humans are currently performing, which in turn are essentially a “workaround” for situations where the core software systems are unable to interoperate.
I fundamentally disagree with this approach for solving application interoperation problems. The general category of this approach to problem solving does have several positive examples. However, I do not believe that process automation falls in the category of problems that can be fixed by such an approach. The problem solving technique that I am referring to is common in various algorithms and mathematical exercises. In simple terms the technique involves taking a problem and re-expressing it in terms of a different set of components, and then solving the resulting problem (which is simpler to accomplish), and then transforming the solution back to the original frame. A simple high-school mathematics example could be the multiplication of two large numbers. Here the multiplication problem can be transformed to an addition problem by taking the logarithm of the two numbers. Thus:
For two numbers a and b, the product (a x b) can be solved as:
log(a x b) = log a + log b
once the sum of log a and log b is determined, the antilog of this value:
antilog(log a + log b)) = a x b
By this logic, some people may argue that the problem of application interoperation can be solved by transforming it into a problem of human actions and then applying artificial intelligence frameworks to solve this problem, and thus solve application interoperation problems.
The reasons why I believe that this technique is not applicable in interoperation problems is because:
- There does not exist any automatic and formulaic conversion of the original problem space (the un-integrated applications) into a sequence of human actions. “Process discovery” / “process mining” is performed on processes that are already being conducted manually as software-driven-labour.
- The kinds of problems that exist in the software driven labour space such as document reading and understanding, are far more complex to solve than the original interoperation problem. Furthermore, the artificial intelligence based solutions for document recognition are always less than 100% accurate over a wide range of document types and formats.
In the case of process integration through application interoperation, the lack of suitable straight through processing capabilities has resulted in the problem being tossed over the fence from the IT department to the operations departments. Remember the “long tail of integration value” diagram in a previous article? In real-life scenarios, the IT department will present the cost of transformation and integration to the business group, who will then decide to adopt the then-cheaper (please not this: then-cheaper) alternative of getting operations staff or outsourced staff to perform the steps manually via software driven labour. Now, on the other side of the wall, in the business operations space, the cost of labour is calculated and summed over all the SDL based processes that the business operations has unwittingly undertaken to perform. The cost of SDL is borne by the business. If a solution is proposed that can reduce this cost by 20% to 30% and more, any CFO will sit up and listen.
Improving efficiency and reducing human costs for “dull, repeatable” processes has been the manifesto of products and services companies in the new generation hyperautomation space. This will never result in fixing the real problem and enabling straight through processing of all business activities.
Given how things have turned out in the business process execution space, it may seem that there is no other solution than to continue on the trajectory set by hyperautomation. This means continuing to improve the activities in Box B by creating better AI based functionalities to read and digitise documents and to discover processes by analysing recordings of software driven labour activities.
I disagree with that approach. According to me, the effort to automate and enable STP must concentrate on Box A activities. When that is accomplished successfully, Box B will disappear – there will be no need for software driven labour and to apply AI techniques to mimic human actions.
To achieve this the following two aspects need to be handled:
- Sending and receiving data in fully digital form.
- Easy composition and configuration of process flows in Box A
One of the biggest and most fundamental issues has been the problem of inter-organisation digital data exchange. Limited inter-organisation data exchanges have existed in the form of electronic data interchange (EDI) and B2B Gateways. Inter-organisation financial transactions and settlements have also been successfully achieved. Payment systems such as SWIFT are examples of such successful digital data exchanges.
In the past, the main issues preventing the widespread deployment of such inter-organisation exchanges has been the formidable cost of setting up the exchange infrastructure in each participating organisation. Software products such as IBM MQ Series and TIBCO promised a world where digital messages can be broadcast or published securely and only the intended recipients are able to receive it and onward process it. Such message-oriented-middleware (MOM) continue to be the principal mechanism for enterprise application integration (EAI) as well.
It was the inability to formulate appropriate inter-organisation digital exchanges that led to the prevailing de-digitized document exchanges between organisations and the subsequent deployment of software driven labour to re-digitise the data and to perform the remaining workflows.
In 2017, after I moved on from the acquirers of my “RPA” company, I spent considerable time on the drawing board to understand the real causes of software driven labour and to formulate that ONE solution that would finally close the chapter and the book of enterprise data and process integration. UI-Integration (RPA) is definitely an important tool in this solution, but it’s use in Box B was an issue. We needed to move it back to Box A.
Telligro, the company that I founded, is focused on this solution. With the availability of cloud, virtualisation, containerisation, AI, RPA, and EAI ‘on tap’, the timing is right for the new process integration technology to be rolled out. The other key characteristic is that the solution has to be vertical-agnostic and horizontal-agnostic. That is, unlike many contemporary “verticalised SaaS” offerings, this solution’s key value proposition is that it can harbour multiple vertical and horizontal job functions. I will discuss the details of our solution in a separate article.
Apart from being a shameless “plug”, the purpose of mentioning my company’s solution at this point is to provide a concrete example of a solution to the “universal business integration” problem. Over the past several decades, the lack of an appropriate solution to this problem has resulted in the use of low fidelity solutions starting with software driven labour and all the way up to hyperautomation.
The second issue: that of process encoding and composition is also being addressed by Telligro. Unlike the silly stuff that people are doing in Box B – requiring the use of ML and AI to understand software driven labour behaviours – we are focused on Box A activities. In Box A, we can make use of robust and reliable algebraic methods to define and compose workflows. Again, I will elaborate these capabilities in a separate article.
Those with vested interest in hyperautomation (including AI, RPA etc) may wish to interject here and point out that there are many automation solutions that require AI based actions. They may cite use cases and examples such as Fraud Detection that may be performed by humans using heuristic techniques, which now have an AI based alternative. My response to that argument is that I am certainly in favour of AI based business applications. My issue is with the use of AI to automate software driven labour. It is perfectly fine to have business application that may use AI techniques as opposed to traditional “if-then” rules to solve a problem or reach an inference from available data. Continuing the above example, it is perfectly fine to have a new software application in Box A that makes use of AI techniques to analyse incoming data and detect fraudulent transactions.
Due to the rather open-ended definition of hyperautomation, it has become very easy for people to classify AI-based bona-fide business applications under the hyperautomation category. Don’t forget the evolution of this technology: UI-integration came first; it then morphed to UI Automation when it was used for automating business process flows that were hitherto being performed by humans. UI-Automation was renamed and hype-marketed as RPA. When RPA could not ‘cut it’ for many processes, they added AI based OCR, CV, and process mining to the ride and called it “intelligent automation”. Now, in order to keep the momentum going, they have extended the definition to include “other types of decision, process, and task automation tools”. This will help keep the hyperautomation flame burning for a long time since the definition allows business applications to be classified as hyperautomation.
Think! McFly!! Think!!
I believe this is the end of the road for activities that are based on automating activities in Box B. The timing is right for the world to return to fixing issues in Box A, leaving behind this era of hyper-nonsense called hyperautomation.
In subsequent articles, I will explain the theory behind the new software technology that, I believe, will provide a universal and lasting solution to achieve straight through processing.