
Series: Rethinking
“He lost his key in the dark room. He searched for it in the street, because that is where the light was.”
— Sufi teaching parable
There is a version of this story in almost every wisdom tradition. It will not go away, because the pattern it describes will not go away — people search where it is easy, not where the answer is. The enterprise software industry is doing this right now, at a scale that would have impressed the Sufis, throwing its most powerful technology at the place where the problem is most visible. The architectural failure that actually created the problem sits in the dark room of the integration layer, and nobody is looking.
In brief: The marquee categories of enterprise AI — document processing, agentic bots, process mining, and copilots — are all pointed at the workaround layer between systems. Not at the application and application-integration layer, where the problem starts. The same AI could let systems understand each other and exchange data natively — but nobody is aiming it there. This article looks at why.
Organisation X has digital data in its billing system — structured, clean, sitting in a database. It generates a PDF invoice and emails it to Organisation Y. At Organisation Y, an AI-powered system — maybe an LLM with multimodal capabilities, maybe OCR augmented with computer vision — reads the PDF, extracts the data fields, validates them, and feeds them into accounts payable. I agree that the accuracy is better than anything three years ago, but step back and see what is really happening. That document was de-digitised into a PDF and then re-digitised using AI. At every step there is more complexity, more cost, and more error risk. The whole pipeline exists to solve a problem that should not exist.
And this is not some edge case. It is the dominant pattern. Across insurance, logistics, banking, healthcare, and trade finance — we are pointing the best AI in the world at structured data that was generated from structured data, wrapped in a PDF along the way for reasons that have almost nothing to do with technology and almost everything to do with organisational boundaries. The AI aimed at this task is extraordinary, but the target is wrong.
The pattern is not new. For twenty years the enterprise world has been polishing the workaround instead of fixing the underlying problem. BPO centres came first — people bridging the gaps between systems that could not talk to each other. RPA bots came next, copying what the people did. AI is the third wave, the most capable by a wide margin. But each generation ended up aimed at the same thing: the gap between systems, not the systems themselves.
The Architecture of the Workaround
Every enterprise runs on a collection of core systems — ERP, CRM, billing, compliance, claims management, and trade execution. They are islands in an archipelago, each built to do its particular job well. I call these Box A: the systems where data processing happens, where business logic lives, and where transactions get authorised. Box A is where value gets created.

Between the islands are gaps where data has to move from one application to another, where a process that starts in one system has to somehow keep going in the next. When those gaps are not bridged by proper integration — and mostly they are not — someone or something bridges them by hand — a person in a back office, a BPO centre, or increasingly an RPA bot or AI agent. This is Box B — the workaround layer, and it exists because Box A’s systems cannot interoperate.
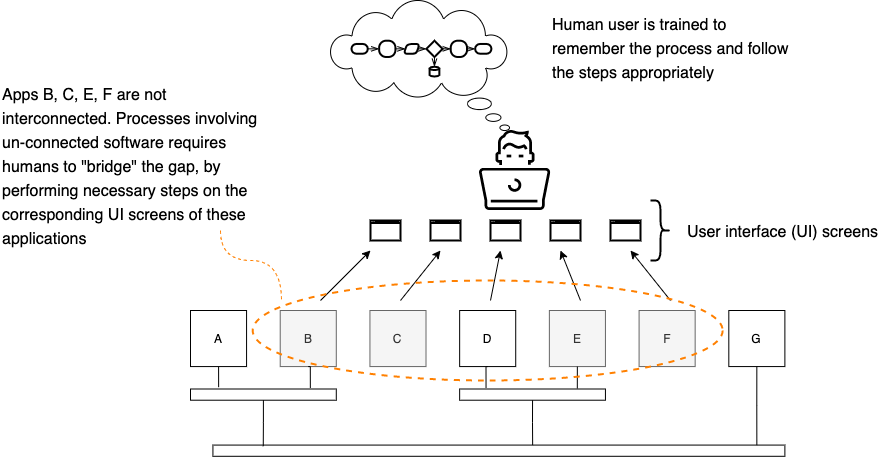
The work in Box B has a precise name: software-driven labour. It is not data entry. It is the manual operation of software user interfaces to move data between systems that should be exchanging it directly — people and bots working as living middleware, carrying data between screens, millions of times a day. The cost runs above $400 billion a year. That takes in BPO operations, back-office processing, shared services, and the growing army of bots and AI agents deployed to make this work faster rather than make it unnecessary.
For a more detailed discussion of Box A – Box B problem, refer to my article 10. Think, McFly! Think!
To know more about my thoughts about Software Driven Labour, refer to my article 1. Software-driven Labour
Why does conventional integration not just fix this? It does — for the big, obvious cases. Middleware, APIs, and enterprise service buses handle the SAP-to-Salesforce connections, core banking to payments gateway. But for every headline integration there are hundreds of smaller ones — a claims system feeding a compliance tool, a logistics platform updating customs, and a trade finance workflow crossing four organisations and seven applications.
I call this the long tail of integration. Each case is too small to justify building, but collectively they are worth more than the headline integrations put together. The long tail is where Box B lives. And it is where AI is now being poured in at scale.
Implementing AI in Box B
I want to be precise about what is happening here, because the cumulative picture matters more than any individual piece of it. The biggest investment is in what the industry calls intelligent document processing — LLMs and multimodal AI extracting data from invoices, claims forms, and shipping documents. I have sat through demos where an LLM takes a crumpled, coffee-stained insurance claim form — handwritten margin notes, three languages, and creases through half the fields — and pulls out every data point. As engineering, it is startling. But the question nags: why is the data in a document at all? It was structured data in the sender’s system before someone hit “Generate PDF.” The AI is cleaning up the tail end of a problem that starts with a failure to exchange data digitally.
Agentic automation is where the architectural confusion gets interesting. AI agents that work their way through application interfaces, make decisions, handle exceptions, and adapt when the UI changes. I have seen an agentic system log into a claims platform, review a submission, cross-check against policy data in a completely different system, flag problems, and route the case for approval — nobody touches a screen.
What that agent is doing, architecturally, is exactly what the human operator was doing — sitting in Box B, operating Box A’s applications through their user interfaces, because the systems themselves will not talk to each other. The agent is vastly more capable than the person it replaced — but the architecture has not moved an inch.
Process mining maps how people interact with applications. The heat maps and flow diagrams can tell you things you didn’t know about your own operations — but what they are showing you is the workaround. When a process mining report says your people spend 40% of their time copying data between the claims system and the compliance platform, that is a symptom. The diagnosis (those two systems lack integration) is a conversation process mining was never built to start. I will not dwell on this one — the pattern is the same.
Copilots and assistants make Box B faster. A claims adjuster reads a policy doc in three minutes instead of twenty, and a trade ops analyst gets through a settlement workflow with fewer mistakes. But they don’t make Box B less necessary. They make it more efficient. That is not the same thing, and I think the distinction gets lost in most conversations about enterprise AI. Efficiency in a workaround makes the workaround more tolerable — which makes it more permanent.
Each investment, on its own, looks rational. The CFO sees clear ROI for everyone. But every dollar invested in Box B deepens the dependence on it. The workaround gets better and more entrenched at the same time.
Every dollar invested in making the workaround more intelligent is a dollar that makes the workaround more permanent.
Nobody is deliberately choosing this. They are choosing Box B by default because its pain is the kind you can see and point at. A claims processor struggling with document extraction — everyone understands that problem. A missing integration between the claims system and the policy administration system — only the integration team knows it exists. And that team stopped asking for a budget years ago.
What AI in Box A Would Look Like
If AI were aimed at the integration layer — at Box A, not Box B — the enterprise would look different in ways that are hard to overstate. And every capability I am about to describe uses technology that is already working in Box B.
Start with semantic mediation. Instead of requiring every application to expose an API or adopt a data standard, an AI-powered integration layer could understand what each application means — its data structures, business logic, and transaction semantics — and mediate between systems that were never designed to talk to each other. A claims system defines a field called “policy_holder_id.” An underwriting system refers to the same entity as “insured_party_reference.” Normally, a human architect maps those relationships by hand, pair by pair. Even automated ontology-based systems will spend time working out these relationships. Organisations will have to purchase common ontology databases. But now, a semantic AI layer could learn the mappings, infer them from context, and keep them up to date as the systems beneath them change.
I want to spend a moment on why canonicalisation — the traditional integration world’s answer to this problem — does not work. Canonicalisation is the idea of driving every system toward a common standard. Canonical formats, shared ontologies, and universal schemas. It works in some scenarios, such as SWIFT in financial services, EDI in supply chain, HL7 in healthcare, to name a few. Standards matter, as without them, you don’t get network protocols or interbank settlement. But canonicalization cannot touch the long tail. It places the onus to comply on every system — each application must be modified, and each organisation must adopt the standard. The long tail is the long tail precisely because that onus is too expensive at scale. An AI semantic layer sidesteps the whole problem: let each system keep its own metadata, field names, and quirks. The AI translates on the fly. The world does not have to agree on a vocabulary before anything works.
Transaction orchestration — a trade that touches compliance, settlement, booking, and reporting; AI handles the whole thing across systems instead of someone in Box B manually walking it through. Adaptive integration — the vendor announces a major upgrade, and instead of weeks of regression testing, the integration layer adjusts on its own. I will not develop these at length because the architectural principle is the same: take the capabilities out of Box B and put them in the integration layer, where they address the root cause.
Cross-organisational process intelligence is where it really bites. Inside an enterprise, at least the big system pairs are usually connected. Between organisations, the picture is far worse. Only the highest-volume interactions have decent interoperability — B2B gateways, EDI, and SWIFT. Everything else gets handled by turning data into documents.
Purchase orders, bills of lading, certificates of origin, and letters of credit — organisations send these across boundaries, and the other side re-digitises them. AI could let them transact directly. The whole de-digitise-and-re-digitise cycle just goes away. Data stays digital from origin to destination, and the technology to support it is already in place. LLMs that read crumpled insurance forms can interpret application data models, and agentic systems that run workflows can orchestrate transactions — the capability exists, but nobody has pointed it at the right layer.
Why This Is Not Happening
The vendors who dominate enterprise AI automation — RPA platforms, IDP providers, and process mining companies — built their businesses on Box B. Their revenue needs the workaround layer to keep existing. Pointing AI at Box A means cannibalising the problem that pays their bills. You chase the revenue, and it’s in Box B, where the pain is the kind you can see — walk into a BPO centre, hundreds of people copying data between screens. Look at the P&L, and you will find the line item. AI vendors demonstrate “bots” extracting data from an invoice, and the before-and-after story tells itself. Box A’s integration gaps live in system diagrams, middleware configurations, and the invisible space between applications. The integration architects understand them, but those architects don’t control budgets, and most of them gave up making the case years ago.
There is also difficulty — I will not pretend otherwise. Teaching an AI to pull data from a PDF is a well-defined problem. Teaching an AI to understand what two enterprise applications mean, to mediate between data models and business logic and transaction semantics — that is a different class of problem. You need to grasp intent, not just pattern. But difficulty explains a trajectory; it does not justify one. And the integration problem gets worse the longer you ignore it. Unlike document extraction, it compounds.
There is an idea in integration architecture — “the onus to comply” — a term I coined a few years ago. Who carries the burden of making integration work? The conventional answer is that every participating application in an integrated system bears that burden. Each system exposes an API, adopts a standard, and allows itself to be modified. That is why the long tail never shrinks: more integrations needed than there is budget to build, because each one needs both sides to play along. AI could shift that burden entirely — put it on the integration layer and let it learn to connect to applications without requiring them to change. The integration layer complies, adapts, and figures it out — but that potential stays theoretical as long as the money keeps flowing to Box B.
The Choice
The question for the next decade is not whether to adopt AI — that is settled — but where you point it. The first option, and the default, is to keep putting AI in Box B, making the workaround faster, smarter, and more autonomous. It becomes so capable that it starts to feel like a solution. Organisations keep investing, dependency deepens, and the integration gaps in Box A persist — permanently hidden behind the AI machinery that has grown up around them.
Second option — the traditional integration answer. Canonicalise, drive common standards, APIs, and enforce schemas. It works for the big integrations and always has, but it has not cracked the long tail in thirty years because it needs every system to comply.
Third — migrate the AI out of Box B and into Box A. Progressively digitise the exchanges that currently need workarounds. Not by scrapping document ingestion, but by moving it into the integration layer, making it part of Box A’s infrastructure instead of Box B’s coping mechanism. The same AI that pulls data from PDFs becomes the front end of a semantic mediation pipeline. It reads the messy, unstructured inputs from how organisations actually exchange information, translates them into the receiving system’s native structure, and eventually — as both sides digitise — phases itself out.
The question is not whether AI can automate the workaround. It can. The question is whether we want it to — or to eliminate the need for the workaround altogether.
We should start with what we have — document ingestion, agentic workflows, and semantic understanding — and move them into the integration layer, where they go after the root cause of the integration issue is identified. We build AI that translates metadata structures on the fly, rather than waiting for every system to adopt a canonical format, and you digitise the exchanges that currently degrade into documents at every organisational boundary. Each step shrinks Box B and shortens the long tail a bit.
Twenty years ago, the enterprise world hired people to bridge the gaps, and ten years ago, it deployed bots to copy what the people did. Today, it is deploying AI to make everything faster. The technology has become more impressive at each stage, but the underlying problem has stayed exactly where it was. AI is the first technology powerful enough to address the integration problem at its root, and whether the industry uses it for that — or keeps pouring it into workarounds — will define the next decade of enterprise architecture. The data was digital, then de-digitised, and then re-digitised using AI. At some point, someone will ask why.
For the constructive companion to this article — what AI in Box A looks like concretely, and why the agentic capability belongs in the integration stack — see “Rethinking AI for Automation: Copilot Is Not the Architecture.” For the full backstory of how enterprise integration failed, how RPA was born and redirected, and why the $400 billion workaround economy persists, see The Foundations. For what AI-in-Box-A looks like when it works, see “Rethinking the Transaction.”
Madhav Sivadas is an enterprise software integration architect with nearly thirty years of experience in process integration, UI automation, and enterprise workflow. He founded Inventys (acquired in 2012), holds multiple US patents in software integration, and is the founder and CEO of Telligro, building AI-driven intelligent transaction networks for insurance, logistics, and financial intermediaries.